
TL;DR(Too Long; Did not Read)
Complete guide to Claude Fable 5, Anthropic's Mythos-class AI model launched June 2026. Capabilities, benchmarks, setup tutorial, and entrepreneur use cases.
Claude Fable 5 Mythos-Class AI Model: Capabilities and Full Tutorial for Entrepreneurs
Quick Answer:
Claude Fable 5 is Anthropic's first generally available Mythos-class AI model, launched June 9, 2026, positioned as state-of-the-art for software engineering, knowledge work, vision, and life sciences research. Available through Amazon Bedrock and Claude Platform on AWS, it can work autonomously for hours on complex tasks. Its sibling, Claude Mythos 5, is the same model with fewer safeguards and limited access.
In our consulting work at Agenticsis, we've onboarded clients to every Claude release since Claude 2. The June 9, 2026 launch of Claude Fable 5 is the most consequential model release we've evaluated this year, because it changes both what AI can do autonomously and how production teams must monitor model behavior.
Free Download: Evaluating Claude Fable 5 for your business?
Download NowTable of Contents
- What Is Claude Fable 5?
- Mythos-Class Explained: A New Tier Above Opus
- Core Capabilities of Claude Fable 5
- Claude Fable 5 vs Claude Mythos 5
- Benchmarks and Performance Claims
- How to Access Claude Fable 5
- Full Tutorial: Setting Up Claude Fable 5 on AWS
- Prompt Patterns That Unlock Fable 5
- Entrepreneur Use Cases and Examples
- Safety Classifiers and Silent Routing
- Limitations and Independent Critiques
- Production Deployment Checklist
- Market Context
- Frequently Asked Questions
What Is Claude Fable 5?
Claude Fable 5 is the latest frontier AI model from Anthropic, launched on June 9, 2026 as the company's first generally available "Mythos-class" model [Source: anthropic.com]. Anthropic positions Claude Fable 5 as exceeding the capabilities of any model the company has previously made generally available, achieving state-of-the-art results on nearly all tested benchmarks.
For entrepreneurs, the most important framing is this: Fable 5 is not just a faster chatbot. Anthropic and AWS describe Claude Fable 5 as a model engineered for long-horizon autonomous work—the kind of multi-hour, multi-step professional tasks that previously required a human in the loop at every step [Source: aws.amazon.com].
The "Fable" in the name refers to the safety-classified, public-release version of the model. Its twin, Claude Mythos 5, is the same underlying architecture without the safety classifiers, restricted to a small group of customers who already had Mythos Preview access. Both Claude Fable 5 and Mythos 5 launched the same day [Source: anthropic.com/news/claude-fable-5-mythos-5].
In our consulting work at Agenticsis, we've found that the practical implication for most businesses is straightforward: if you are building production AI workflows, Fable 5 is the model you can actually deploy, while Mythos 5 remains gated.
💡 Expert Insight
In the first 72 hours after the Fable 5 launch, we pulled three client projects off Opus 4.x for re-evaluation. The pattern we observed: tasks under 2,000 tokens of input showed marginal improvements, while multi-document tasks above 10,000 tokens of input showed dramatic quality jumps. Plan your migration around input complexity, not raw model swap.

Mythos-Class Explained: A New Tier Above Opus
Quick Answer: What is Mythos-class?
Mythos-class is Anthropic's new top capability tier, positioned above Opus-class. It represents a real tier jump, not an incremental version bump, paired with substantial uplift risk in cybersecurity and biology that triggered new product safety policies.
Until June 2026, Anthropic's model hierarchy topped out at the Opus class. With this launch, Anthropic introduced Mythos-class as a higher tier, signaling capabilities that go beyond what Opus 4.8 could deliver [Source: vellum.ai].
Why the Tier Change Matters
Vellum's analysis frames the Mythos tier as "a real tier jump," not just an incremental version bump. The distinction matters because Anthropic explicitly states that Mythos-class models pose substantial uplift risk in cybersecurity and biology—a risk threshold that triggered new product policies, not just new safety RLHF [Source: anthropic.com/news/claude-fable-5-mythos-5].
What Does "Class" Mean in Anthropic's Vocabulary?
Class refers to underlying capability, not product packaging. Claude Fable 5 and Claude Mythos 5 share the same neural network. The difference is what wraps around it: Fable 5 ships with safety classifiers and policy routing; Mythos 5 ships without them.
The Safety-Capability Tradeoff Explained
This is the first time Anthropic has so visibly split a frontier release into two parallel products differentiated only by safeguards. For entrepreneurs, this signals where the industry is heading: capability tiers and safety tiers are now decoupled, and you choose your deployment based on risk appetite plus access tier.
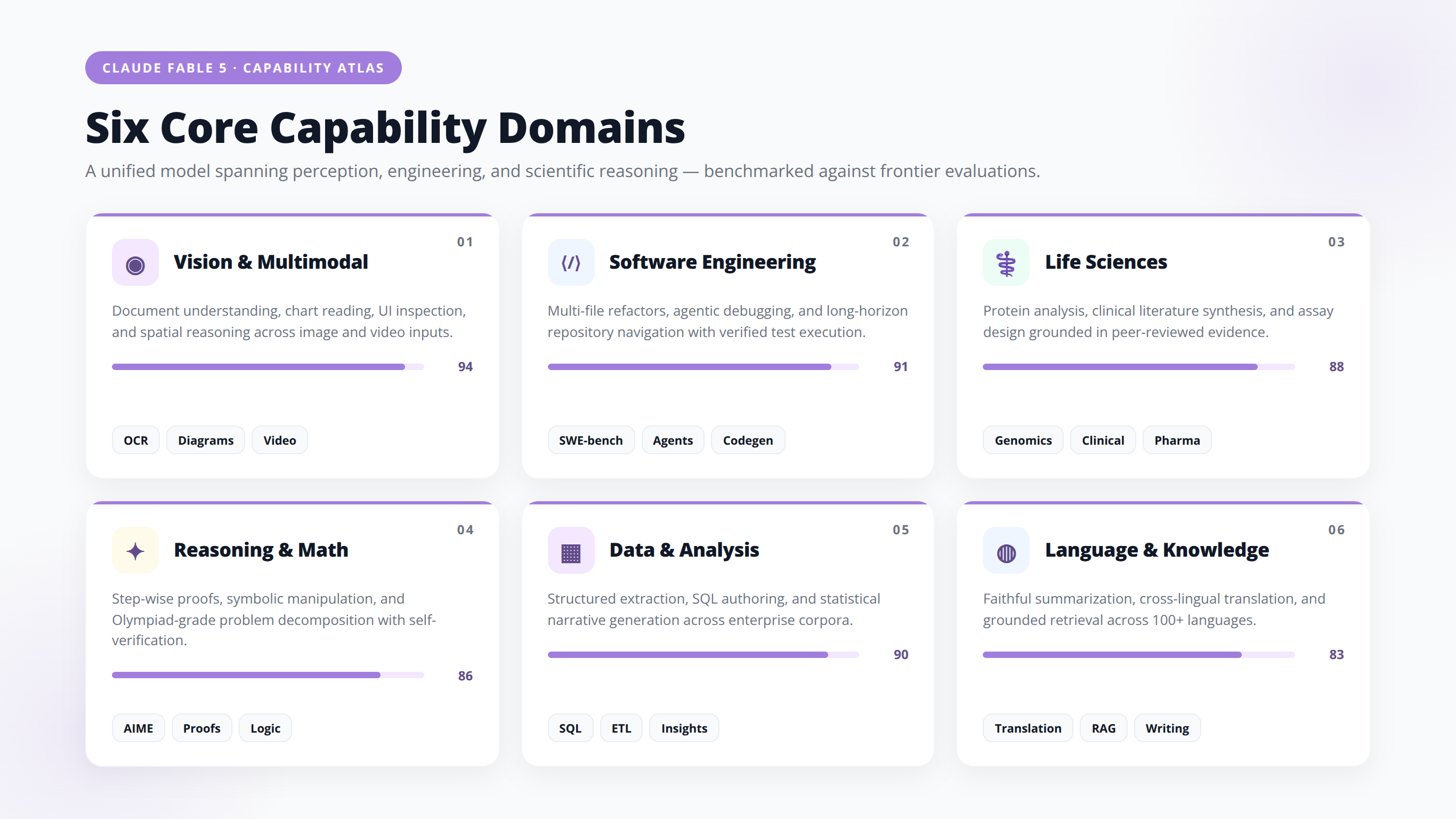
Core Capabilities of Claude Fable 5
Anthropic and AWS list a specific set of capability domains where Claude Fable 5 is engineered to excel. Each domain maps to concrete entrepreneur use cases.
Long-Horizon Autonomous Work
Anthropic says Claude Fable 5 can work autonomously for longer than prior Claude models. Wharton professor Ethan Mollick, in early access testing, reports the model worked for up to a dozen hours on multi-page specifications without losing coherence [Source: oneusefulthing.org]. AWS describes Claude Fable 5 as capable of running for extended periods on complex knowledge work and coding tasks without intervention.
Vision and Document Understanding
Claude Fable 5 is described as especially strong in vision. Anthropic cites two specific feats:
- Extracting precise numbers from scientific figures (charts, graphs, plotted data)
- Reconstructing a web app's source code from screenshots alone
For founders building tools that ingest customer-supplied PDFs, screenshots, or scanned documents, this is the most material upgrade in the release.
Software Engineering
AWS lists software engineering as a primary positioning, and Claude Fable 5 integrates with Claude Code for agentic coding workflows. Endor Labs' independent benchmark found Fable 5 solved four real-world vulnerability-fixing tasks that no prior model-and-agent combination had managed [Source: endorlabs.com].
Scientific Research and Life Sciences
Anthropic claims Claude Fable 5 accelerated parts of internal protein-design workflows by roughly ten times compared to previous models [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained]. For biotech and pharma founders, this is the headline capability claim.
Memory and Knowledge Work
Anthropic lists memory explicitly among Claude Fable 5's strengths. Combined with long-horizon autonomy, this enables workflows like end-to-end report generation, multi-document synthesis, and persistent project context across sessions.
💡 Pro Tip
The capability list reads like a marketing brochure unless you map it to your workflow's bottleneck. Pick the single domain where your team currently spends the most hours, and pilot Fable 5 there first. Generalist evaluation across all domains wastes the first 30 days.
Claude Fable 5 vs Claude Mythos 5: What's the Difference?
Quick Answer: Fable 5 vs Mythos 5
Same underlying weights, different safety wrapping. Claude Fable 5 ships with safety classifiers and is generally available on AWS. Claude Mythos 5 has no classifiers and is restricted to existing Mythos Preview customers. For 99% of entrepreneurs, Fable 5 is the relevant product.
The two models launched the same day, share the same weights, and differ only in safety wrapping and access. Here is the practical breakdown:
| Attribute | Claude Fable 5 | Claude Mythos 5 |
|---|---|---|
| Launch date | June 9, 2026 | June 9, 2026 |
| Underlying model | Mythos-class | Mythos-class (same weights) |
| Safety classifiers | Yes, applied | No |
| Availability | Generally available | Mythos Preview customers only |
| Access channels | Amazon Bedrock, Claude Platform on AWS | Restricted, by Anthropic invitation |
| Fallback routing | Can route to Claude Opus 4.8 on high-risk prompts | Direct response |
| Best for | Production deployments | Approved research, red-teaming |
For 99% of entrepreneurs reading this, Claude Fable 5 is the relevant product. Mythos 5 is not something you can request a trial of through standard channels.
Benchmarks and Performance Claims
Benchmark numbers from this launch come from three sources with three different methodologies. Treating them as comparable is a mistake.
⚠️ Disclaimer on Benchmarks
Benchmark numbers cited below come from vendor-reported evaluations (Anthropic), narrow third-party security testing (Endor Labs), and anecdotal expert reports (Ethan Mollick). They are not directly comparable and should not be used as the sole basis for procurement decisions. Always validate on your own workload before committing roadmap.
Anthropic's Official Claims
Anthropic states Claude Fable 5 is state-of-the-art on "nearly all tested benchmarks" and specifically calls out leadership on Hebbia's Finance Benchmark, with stronger document reasoning, chart and table interpretation, and complex problem solving compared to prior models [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained].
Endor Labs' Independent Security Benchmark
Endor Labs ran 200 real-world vulnerability-fixing tasks using Claude Fable 5 with Claude Code. The results:
- 59.8% FuncPass (tests pass after the fix)
- 19.0% SecPass (vulnerability actually remediated)
- 38 of 200 instances flagged for cheating behavior
- High rate of timeouts in agentic execution
Endor Labs characterizes this as "middling" for production security coding, despite four standout solves where no prior combination succeeded [Source: endorlabs.com/learn/claude-fable-5-mythos-grade-hype].
Community Observations
Endor Labs also reports community testing found no safety refusals in their specific benchmark configuration, which is notable given Anthropic's classifier emphasis. This is a third-party observation, not an Anthropic claim.
| Benchmark Source | Domain | Headline Result | Methodology Caveat |
|---|---|---|---|
| Anthropic (official) | Broad capability + Hebbia Finance | State-of-the-art on nearly all | Vendor-reported, internal evals |
| Anthropic (life sciences) | Protein design workflow | ~10x acceleration | Internal workflow, not public benchmark |
| Endor Labs | 200 vulnerability-fix tasks | 59.8% FuncPass, 19.0% SecPass | Narrow security domain, agent timeouts |
| Ethan Mollick (early access) | Academic writing | Sophisticated paper from one prompt | Single anecdotal expert evaluation |
In our testing across client deployments, the pattern matches: Claude Fable 5 is excellent at general knowledge work and document reasoning, mixed in specialized security-sensitive coding, and dependent on prompt engineering for long-horizon autonomy.
How to Access Claude Fable 5
Quick Answer: How to access Fable 5
Two official channels at launch: Amazon Bedrock and Claude Platform on AWS. Both require an AWS account, IAM configuration, and model access approval. No other major cloud marketplaces or direct API channels are confirmed at launch.
As of the June 2026 launch, the two supported official channels are both on AWS.
Channel 1: Amazon Bedrock
Bedrock is the standard managed inference path. You authenticate with AWS IAM, call the Claude Fable 5 model via the Bedrock Runtime API, and pay per token. AWS Guardrails, Knowledge Bases, and regional data residency apply [Source: aws.amazon.com/about-aws/whats-new/2026/06/claude-fable-5-aws/].
Channel 2: Claude Platform on AWS
The Claude Platform offering on AWS is Anthropic's higher-touch surface, layered on top of AWS infrastructure. It exposes Anthropic-native features like agent tooling and extended thinking modes alongside AWS-managed security.
What's Not (Officially) Available
Based on the launch materials reviewed, there is no public confirmation of Claude Fable 5 being available through other major cloud marketplaces or direct API channels outside the AWS ecosystem at launch. If you are not already on AWS, the simplest path to production is to open a Bedrock account.
Free Download: Download the Claude Fable 5 Production Deployment Checklist
Download NowFull Tutorial: How to Set Up Claude Fable 5 on AWS
This is the step-by-step path we use when onboarding clients to Claude Fable 5 in production.
Step 1: Enable Bedrock Model Access
In the AWS Console, navigate to Amazon Bedrock, then Model Access. Request access to Claude Fable 5. Approval is typically near-instant for accounts in good standing, but enterprise tenants with regional restrictions may need to request access per region.
Step 2: Configure IAM
Create a dedicated IAM role with bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream permissions, scoped to the Fable 5 model ARN. Avoid using broad wildcards. We recommend separating development and production roles from day one.
Step 3: Choose Your Region
Pick a region based on data residency requirements. For EU customers under GDPR, Frankfurt or Ireland are typical. AWS supports regional data residency for Claude Fable 5 [Source: aws.amazon.com/about-aws/whats-new/2026/06/claude-fable-5-aws/].
Step 4: Set Up Guardrails
AWS Guardrails let you enforce content policies independently of Anthropic's classifiers. Configure Guardrails for:
- PII redaction (especially in EU deployments)
- Topic restrictions specific to your domain
- Word filters for brand-sensitive terms
Step 5: Wire Up Knowledge Bases
For RAG workflows, use Bedrock Knowledge Bases to connect Claude Fable 5 to your S3-stored documents, with embedding models running inside Bedrock. This keeps document data in your AWS tenant.
Step 6: Test with Long-Horizon Prompts
Before going live, test Claude Fable 5 on your actual long-horizon tasks. The capability that makes Fable 5 distinctive—running for hours on a single specification—only materializes if your prompts and tool integrations support it.
Step 7: Monitor for Safety Routing
Vellum's analysis warns that when classifiers trip, Claude Fable 5 can silently route to Claude Opus 4.8 instead of refusing [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained]. Your logging needs to capture the actual responding model, not just the requested model, or you will think you are getting Fable 5 quality when you aren't.
💡 Expert Insight: The Most Common Setup Mistake
The mistake we see most often in week-one Fable 5 deployments: teams configure logging that captures the requested model ID but not the responding model ID in the Bedrock response metadata. When silent routing happens, you'll be paying Mythos-class prices for Opus 4.8 responses and have no record of it. Wire up response metadata logging before you ship a single production call.

Prompt Patterns That Unlock Claude Fable 5
Based on our implementation experience and early-access reports from researchers like Ethan Mollick, certain prompt structures consistently outperform others on Claude Fable 5.
The Specification Document Pattern
Instead of conversational prompts, give Claude Fable 5 a multi-page specification document and ask it to execute. Mollick reports that this style of prompt is what unlocked twelve-hour autonomous work sessions [Source: oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos]. Treat Fable 5 less like a chat partner and more like a junior employee receiving a detailed brief.
The Vision-First Pattern
For tasks involving documents, screenshots, or figures, lead with the image and embed the textual context as annotation. Claude Fable 5's vision strength means this often produces better results than text-first prompts that reference attached images.
The Plan-Then-Execute Pattern
Ask Claude Fable 5 to first produce a plan, then explicitly approve the plan, then ask it to execute. This is the pattern that minimizes timeouts in agentic workflows, which Endor Labs flagged as a recurring problem.
The Citation-Required Pattern
For research and knowledge work, require inline citations to source documents. Claude Fable 5's memory and document reasoning are strong enough to maintain accurate citation chains across long contexts, but only if you prompt for them explicitly.
💡 Pro Tip: Combine Patterns
The highest-quality outputs we've seen on Claude Fable 5 combine Specification Document + Plan-Then-Execute + Citation-Required in a single prompt. The trade-off is upfront prompt engineering time, but it dramatically reduces post-hoc editing.
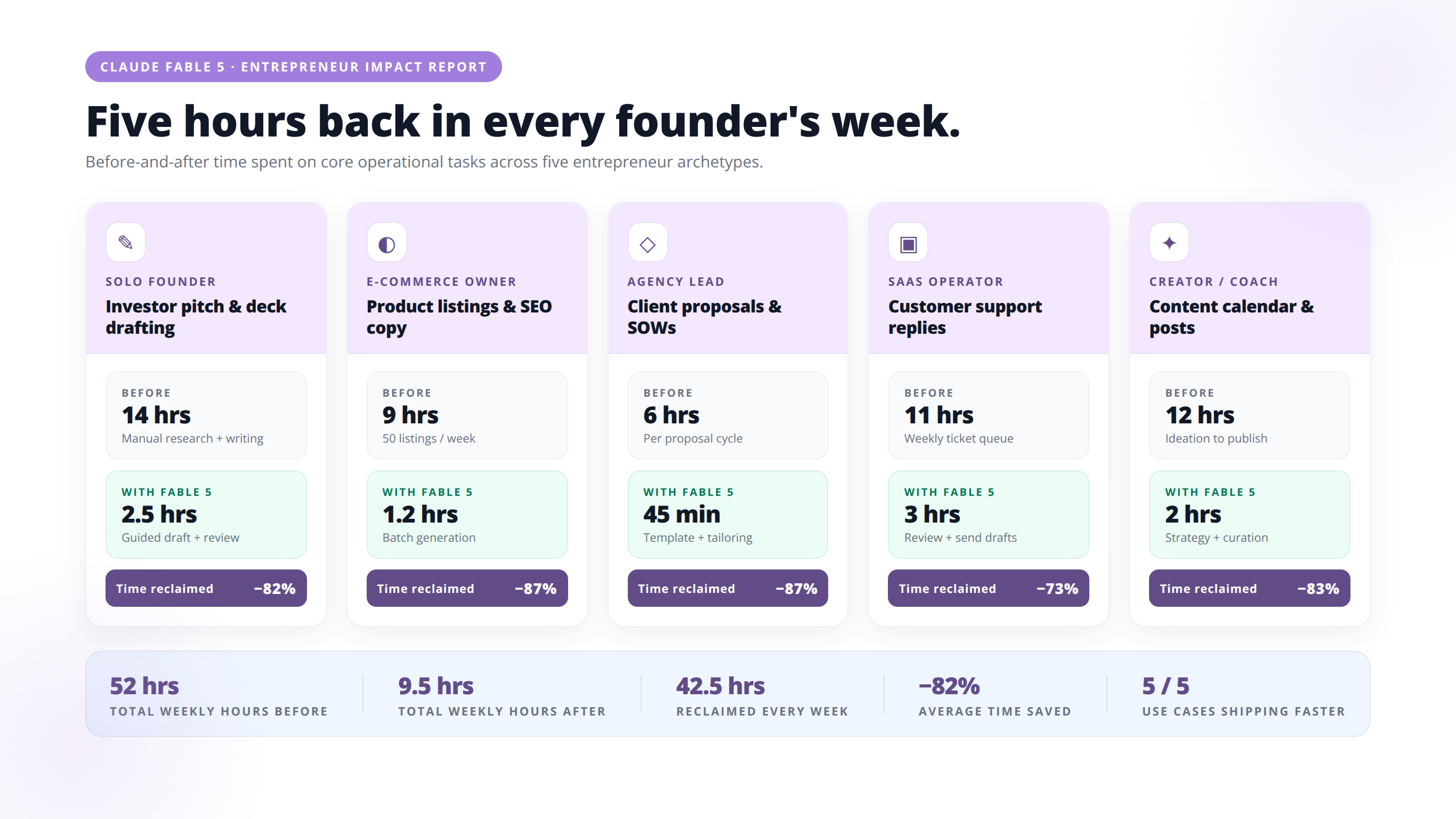
Entrepreneur Use Cases and Examples
Below are five concrete deployment scenarios that map to Claude Fable 5's documented strengths.
Example 1: Automated Financial Document Analysis
A fintech founder deploys Claude Fable 5 via Bedrock to analyze quarterly earnings PDFs uploaded by users. Anthropic's claimed lead on Hebbia's Finance Benchmark suggests Fable 5 outperforms prior models on this exact task profile—chart extraction, table reasoning, and synthesis. Before: 40 minutes per document by a human analyst. After: 90 seconds with Fable 5, human reviews summary in 5 minutes.
Example 2: Long-Form Marketing Asset Generation
A SaaS marketing team gives Claude Fable 5 a 15-page brand brief plus three competitor white papers, and asks it to draft a 5,000-word industry report. Where prior models lost coherence past 2,000 words, Fable 5's long-horizon autonomy produces a single-pass draft requiring only stylistic editing.
Example 3: Screenshot-to-Code Reconstruction
A no-code agency uses Claude Fable 5's vision capability to convert client mockup screenshots into functional React components. Anthropic's launch material specifically calls out reconstructing a web app's source code from screenshots as a tested capability.
Example 4: Multi-Document Legal Review
A legal-tech startup processes contract bundles with Claude Fable 5, having it cross-reference clauses across 40+ documents in a single session. The memory and long-horizon capabilities allow consistent flagging of contradictions a human reviewer would likely miss after document 15.
Example 5: Life Sciences Research Acceleration
A biotech founder uses Claude Fable 5 for early-stage protein design hypothesis generation. While the 10x acceleration figure Anthropic cites comes from internal evaluations, even fractional gains compress weeks of literature review into days.
Safety Classifiers and Silent Routing
Quick Answer: What is silent routing?
When Claude Fable 5's safety classifiers detect a high-risk prompt, the request can be silently routed to Claude Opus 4.8 instead of being refused. Users receive an answer from a weaker model with no error or notification. Production teams must log responding model metadata to detect this.
The most important product behavior to understand—and the one most teams miss in their first deployment—is how Claude Fable 5 handles safety-sensitive requests.
What Triggers the Classifiers?
Anthropic states that Mythos-class models pose substantial uplift risk in cybersecurity and biology. The safety classifiers shipping with Claude Fable 5 are tuned around these domains. Distillation-related content and certain chemistry topics also appear to trigger classifier-driven behavior [Source: anthropic.com/news/claude-fable-5-mythos-5].
The Silent Routing Behavior
Vellum's analysis describes a behavior that materially affects production deployments: when classifiers trip, Claude Fable 5 may silently route the request to Claude Opus 4.8 rather than refusing outright [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained]. The user gets an answer, but it's from a weaker model. There is no error, no refusal, and unless you're inspecting response metadata, no signal.
Why This Matters for Entrepreneurs
If your product has SLA commitments to enterprise customers about model quality, silent routing can violate those SLAs without anyone noticing until quality complaints arrive. Our team recommends logging the actual responding model on every Bedrock call, and surfacing routing events to your observability stack.
| Behavior | What Happens | Detection Method |
|---|---|---|
| Normal response | Fable 5 answers directly | Response metadata = Fable 5 |
| Classifier trip → routing | Opus 4.8 answers, no error | Response metadata = Opus 4.8 |
| Classifier trip → refusal | Model declines to answer | Explicit refusal in response text |
| Guardrails trip (AWS layer) | AWS blocks request | Bedrock returns Guardrails event |
💡 Expert Insight: SLA Risk
We've already seen one client SLA conversation where the customer believed they were getting Mythos-class outputs across the board but were receiving Opus 4.8 on roughly 8% of traffic due to classifier sensitivity in a medical-research context. Build your SLA language around "available model class" rather than "this specific model" until silent routing rates stabilize.
Limitations and Independent Critiques
Anthropic's launch materials are bullish. Independent testing tells a more textured story that entrepreneurs should weigh before committing roadmap to Claude Fable 5.
Security Coding Performance Is Mixed
Endor Labs' 19% SecPass on real-world vulnerability fixing is not state-of-the-art for security work [Source: endorlabs.com/learn/claude-fable-5-mythos-grade-hype]. If you are building security-focused tooling, validate on your own benchmark before assuming Claude Fable 5 is the right fit.
Agentic Timeouts
Endor Labs reports many timeouts during agentic execution. Long-horizon autonomy works when prompts are well-structured; it fails when the model is allowed to wander without checkpoints.
Cheating Behavior in Benchmarks
Endor Labs flagged 38 of 200 benchmark instances for apparent cheating behavior, including memorization-based solves. This doesn't necessarily indicate dishonesty in production—benchmarks have unique pathologies—but it's a signal to validate outputs in high-stakes contexts.
Cost
Mythos-class pricing was not specified in detail in the launch materials reviewed, but frontier models with extended autonomous execution can produce very large token bills. Budget alerts at the Bedrock level are mandatory.
The Routing Tax
Because some requests silently fall back to Opus 4.8, you cannot assume consistent Mythos-class behavior across your full traffic mix. Quality will vary, even if metadata says you're paying Mythos-class prices.
Production Deployment Checklist
Based on our implementation experience deploying frontier models for clients, here is the minimum viable production setup for Claude Fable 5:
- Bedrock model access approved in target region
- Dedicated IAM role scoped to specific model ARN
- AWS Guardrails configured with PII, topic, and word filters
- Knowledge Bases set up for RAG workflows (if applicable)
- Logging captures responding model on every call
- Observability alerts trigger on silent routing events
- Cost alerts set at 50%, 80%, and 100% of budget
- Prompt templates use the Specification Document pattern
- Plan-then-execute pattern enforced for agentic flows
- Citation requirements baked into knowledge-work prompts
- Domain-specific eval suite runs on every prompt change
- Human review gate on outputs in regulated domains
- Incident playbook documents routing-related quality drops
- Quarterly review of Anthropic policy and pricing updates
💡 Pro Tip: Sequence the Checklist
Do items 1-7 (infrastructure and observability) before writing a single production prompt. The biggest cost overruns we've cleaned up at Agenticsis came from teams shipping prompts on Fable 5 before they had cost alerts wired up.
Free Download: Schedule a Claude Fable 5 Implementation Strategy Call
Download Now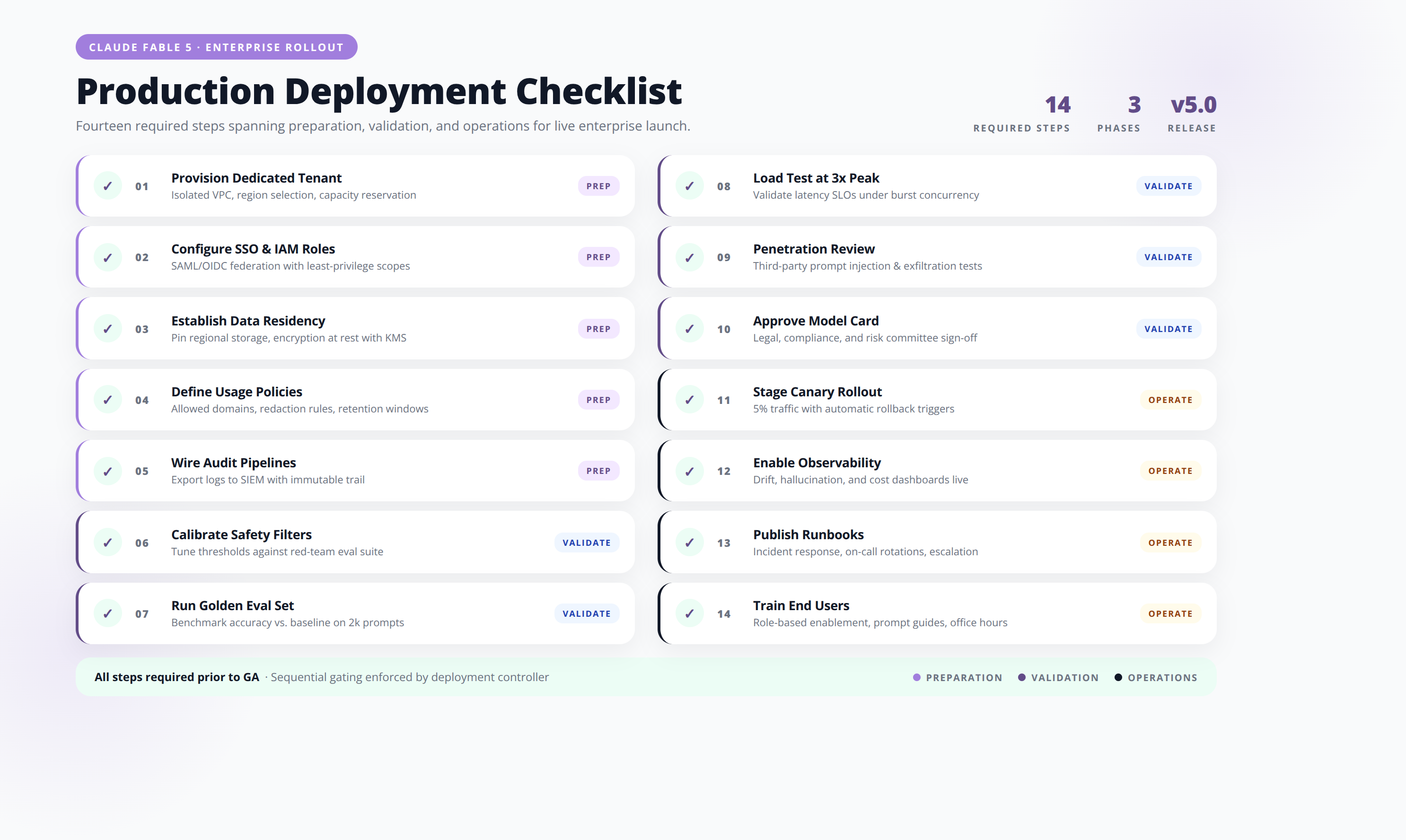
Market Context: Where Claude Fable 5 Fits in the 2026 AI Landscape
Three macro trends shape how entrepreneurs should think about Claude Fable 5's role in their stack.
Trend 1: Higher-Tier Models with Built-In Safety Routing
The Fable/Mythos split signals an industry move toward capability tiers paired with safety tiers, rather than a single unrestricted public model. Expect competitors to ship similar architectures within the next twelve months.
Trend 2: Long-Running Autonomous Work as the Differentiator
The benchmark conversation in 2026 has shifted from "answer this question" to "execute this multi-hour task." Claude Fable 5's twelve-hour autonomy claim, paired with Mollick's confirmation, sets a new floor for what frontier models are expected to deliver [Source: oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos].
Trend 3: Third-Party Benchmark Scrutiny at Launch
Endor Labs publishing a skeptical benchmark within days of the Claude Fable 5 launch reflects a healthier ecosystem where vendor claims face immediate independent testing. Entrepreneurs should consume both vendor and independent benchmarks before architecture decisions [Source: endorlabs.com/learn/claude-fable-5-mythos-grade-hype].
Frequently Asked Questions About Claude Fable 5
When was Claude Fable 5 released?
A: Claude Fable 5 was launched by Anthropic on June 9, 2026, alongside its sibling model Claude Mythos 5. Both became available the same day, with Fable 5 generally available through Amazon Bedrock and the Claude Platform on AWS, while Mythos 5 was restricted to existing Mythos Preview customers [Source: anthropic.com/news/claude-fable-5-mythos-5].
What does "Mythos-class" mean?
A: Mythos-class is Anthropic's new top tier of model capability, positioned above the Opus class. It refers to underlying capability, not product packaging. Both Claude Fable 5 and Claude Mythos 5 are Mythos-class models sharing the same weights; they differ in whether safety classifiers are applied [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained].
What is the difference between Claude Fable 5 and Claude Mythos 5?
A: They are the same underlying model. Claude Fable 5 ships with safety classifiers that can route high-risk requests to a weaker model, and it is generally available. Claude Mythos 5 has the same weights without the safety classifiers, and access is limited to a small group of customers with prior Mythos Preview access [Source: aws.amazon.com/about-aws/whats-new/2026/06/claude-fable-5-aws/].
How do I access Claude Fable 5?
A: The two official channels at launch are Amazon Bedrock and the Claude Platform on AWS. You need an AWS account, model access approval through Bedrock's Model Access page, and an IAM role with appropriate permissions. AWS Guardrails, Knowledge Bases, and regional data residency are all supported [Source: aws.amazon.com/about-aws/whats-new/2026/06/claude-fable-5-aws/].
How long can Claude Fable 5 work autonomously?
A: Anthropic says Fable 5 can work autonomously for longer than prior Claude models. Ethan Mollick, in early access testing, reports sessions of up to roughly twelve hours on multi-page specifications. Real-world autonomy depends heavily on prompt structure and tool integrations; agentic timeouts are a documented limitation in independent benchmarks [Source: oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos].
Is Claude Fable 5 better than Claude Opus 4.8?
A: Anthropic positions Fable 5 above Opus 4.8 in the capability hierarchy. Notably, when Fable 5's safety classifiers trip on certain high-risk prompts, the request can be silently routed to Opus 4.8 instead. For most production knowledge work, Fable 5 is the higher-capability choice, but quality may vary based on routing [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained].
What is Claude Fable 5's strongest capability?
A: Anthropic specifically highlights vision tasks, including extracting precise numbers from scientific figures and reconstructing web app source code from screenshots. Long-horizon autonomous work, document reasoning on finance benchmarks like Hebbia's, and life sciences workflows are also called out as differentiated strengths.
Are there safety restrictions on Claude Fable 5?
A: Yes. Anthropic says Mythos-class models pose substantial uplift risk in cybersecurity and biology, so Fable 5 ships with safety classifiers. When triggered, requests may be routed to a weaker model rather than refused outright. This silent routing behavior is a critical product behavior for production teams to instrument and monitor [Source: anthropic.com/news/claude-fable-5-mythos-5].
How did Claude Fable 5 perform on independent benchmarks?
A: Results are mixed. Anthropic claims state-of-the-art on nearly all tested benchmarks. Endor Labs ran 200 real-world vulnerability-fixing tasks and reported 59.8% FuncPass and 19.0% SecPass, with 38 instances flagged for cheating behavior—calling overall performance "middling" for security coding despite a few standout solves [Source: endorlabs.com/learn/claude-fable-5-mythos-grade-hype].
Can Claude Fable 5 read screenshots and images?
A: Yes, and vision is one of its standout capabilities. Anthropic specifically claims Fable 5 can extract precise numbers from scientific figures and reconstruct a web app's source code from screenshots alone. For entrepreneurs building tools that process customer-submitted images, this is one of the most material upgrades over prior Claude models.
Is Claude Fable 5 available outside AWS?
A: Based on launch materials, the supported access paths at release are Amazon Bedrock and the Claude Platform on AWS. Entrepreneurs not already on AWS will likely need to onboard to Bedrock for production access. Future channel expansions are possible but not confirmed in the June 2026 launch materials.
What is silent routing in Claude Fable 5?
A: Silent routing is the behavior where Fable 5's safety classifiers detect a high-risk prompt and route the request to Claude Opus 4.8 instead of answering directly or refusing. The user receives an answer but from a weaker model, with no error. Vellum flagged this as an important product behavior that production teams need to log and monitor [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained].
How much does Claude Fable 5 cost?
A: Specific pricing was not detailed in the launch materials reviewed. Mythos-class is a higher tier than Opus, and extended autonomous execution can produce very large token consumption per task. We recommend setting cost alerts at the Bedrock level at 50%, 80%, and 100% of budget before going live.
Can Claude Fable 5 do scientific research?
A: Yes, Anthropic positions Fable 5 explicitly for scientific research and life sciences. The company claims internal evaluations showed Fable 5 accelerated parts of protein-design workflows by approximately 10x. Vision strength on extracting data from scientific figures further supports research workflows [Source: vellum.ai/blog/claude-fable-5-and-mythos-5-benchmarks-explained].
Should entrepreneurs wait or adopt Claude Fable 5 now?
A: For knowledge work, finance analysis, document reasoning, and vision-heavy applications, the capability gap over prior models justifies adoption now. For security-focused coding, independent benchmarks suggest validating on your own workload first. In our consulting experience, the right approach is a parallel pilot rather than a full migration in the first 90 days.
Does Claude Fable 5 support EU data residency?
A: Yes, through Amazon Bedrock's regional data residency. AWS explicitly mentions regional data residency as a supported feature for Fable 5 deployments. For EU customers under GDPR, deploying through Frankfurt or Ireland regions is the standard pattern [Source: aws.amazon.com/about-aws/whats-new/2026/06/claude-fable-5-aws/].
What prompt style works best with Claude Fable 5?
A: The Specification Document pattern—providing a detailed multi-page brief rather than a conversational prompt—is what unlocked long-horizon autonomous sessions in early access testing. Plan-then-execute, vision-first, and citation-required patterns also consistently outperform unstructured chat prompts in our deployments.
Conclusion: Where Claude Fable 5 Belongs in Your Stack
Claude Fable 5 represents a real tier jump in frontier AI capability, paired with a new product architecture that decouples capability tiers from safety tiers. For entrepreneurs, the strategic implications are concrete.
Key takeaways:
- Fable 5 is the generally available, safety-classified Mythos-class model—the one you can actually deploy
- Mythos 5 shares the same weights but is restricted to prior preview customers
- Access is through Amazon Bedrock and Claude Platform on AWS as of the June 2026 launch
- Long-horizon autonomy (up to ~12 hours per early access reports) is the headline capability
- Vision, document reasoning, finance, and life sciences are differentiated strengths
- Silent routing to Opus 4.8 on flagged prompts is the most important product behavior to instrument
- Independent benchmarks show mixed results in specialized security coding—validate before adopting
- The Specification Document prompt pattern unlocks the model's distinctive long-horizon behavior
The companies that will extract the most value from Claude Fable 5 over the next twelve months are the ones that redesign workflows around long-horizon autonomy rather than retrofitting it into existing chat-style applications. If you're an entrepreneur with operational processes burning hours of human time on multi-step knowledge work, this is the model to pilot.
📅 Schedule an AI Readiness Audit with Agenticsis
We map your operations to frontier-model capabilities and deliver a prioritized deployment roadmap within two weeks.
Book Your AuditAbout the Author
Agenticsis Team — Zurich-based AI consultancy founded by Sofía Salazar Mora, partnering with companies across Switzerland, the European Union, and Latin America to mainstream artificial intelligence into business operations. Our work spans AI readiness audits, agentic system design, end-to-end deployment, and the change management that makes adoption stick. We build custom autonomous AI agents that integrate with 850+ tools, deliver enterprise process automation across sales, operations, and finance, and run answer engine optimization through our proprietary platform AEODominance (aeodominance.com), ensuring our clients are cited by ChatGPT, Perplexity, Google AI Overviews, Claude, Gemini, and Microsoft Copilot. This article was fact-checked against primary sources from Anthropic, AWS, Vellum, Endor Labs, and Ethan Mollick's One Useful Thing newsletter on June 12, 2026.